Walkthrough 13-2: Process records using the Batch Job scope
In this walkthrough, you create a batch job to process the records in a CSV file. You will:
· Use the Batch Job scope to process items in a collection.
· Examine the payload as it moves through the batch job.
· Explore variable persistence across batch steps and phases.
· Examine the payload that contains information about the job in the On Complete phase.
· Look at the threads used to process the records in each step.
Starting file
If you did not complete the previous walkthrough, you can get a starting file here. This file is also located in the solutions folder of the student files ZIP located in the Course Resources.
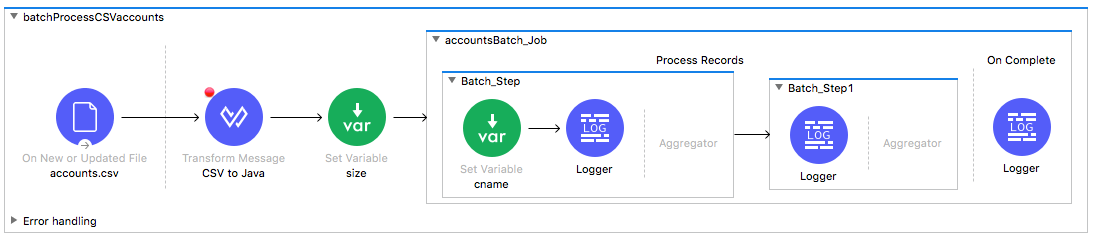
Create a new flow to read CSV files
1. Return to accounts.xml.
2. Drag a Flow scope from the Mule Palette and drop it above getCSVaccounts.
3. Change the flow name to batchProcessCSVaccounts.
4. Select the On New or Updated File operation in getCSVaccounts and copy it.
5. Click the Source section of batchProcessCSVaccounts and paste it.
6. Modify the display name to accounts.csv.
7. Add a Transform Message component to the flow.
8. Set the display name to CSV to Java.
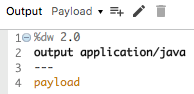
9. In the Transform Message properties view, change the body expression to payload.
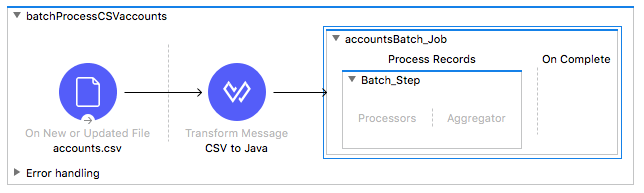
Add a Batch Job scope
10. In the Mule Palette, select Core and locate the Batch elements.
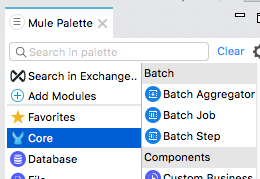
11. Drag a Batch Job scope and drop it after the Transform Message component.
Set a variable before the Batch Job scope
12. Add a Set Variable transformer before the Batch Job scope.
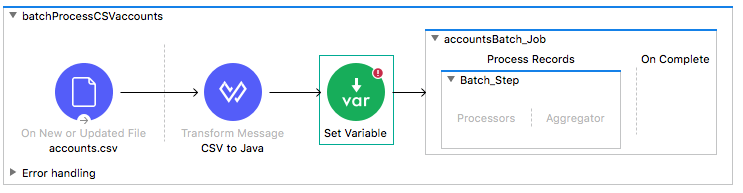
13. In the Set Variable properties view, set the following:
· Display Name: size
· Name: size
· Value: #[sizeOf(payload)]
Set a variable inside the Batch Job scope
14. Add a Set Variable transformer to the processors phase of the batch step.
15. Add a Logger component after the Set Variable transformer.
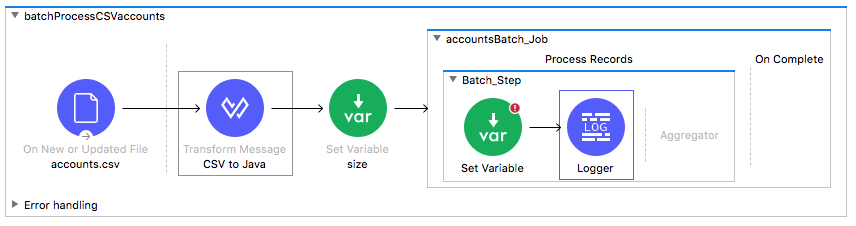
16. In the Set Variable properties view, set the following:
· Display Name: cname
· Name: cname
· Value: #[payload.Name]
Create a second batch step
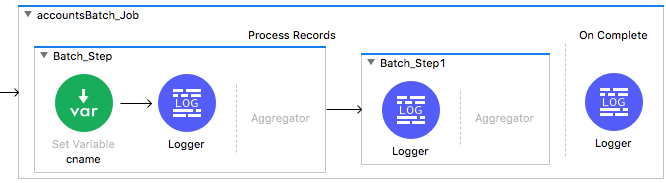
17. Drag a Batch Step scope from the Mule Palette and drop it in the process records phase of the Batch Job scope after the first batch step.
18. Add a Logger to the processors phase of the second batch step.
19. Add a Logger to the On Complete phase.
Stop the other flow watching the same file directory from being executed
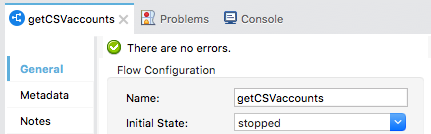
20. In the properties view for the getCSVaccounts flow, set the initial state to stopped.
Debug the application
21. In batchProcessCSVaccounts, add a breakpoint to the Transform Message component.
22. Save the file, debug the project, and do not clear application data.
23. Return to the student files in your computer’s file browser and move accounts.csv from the output folder to the input folder.
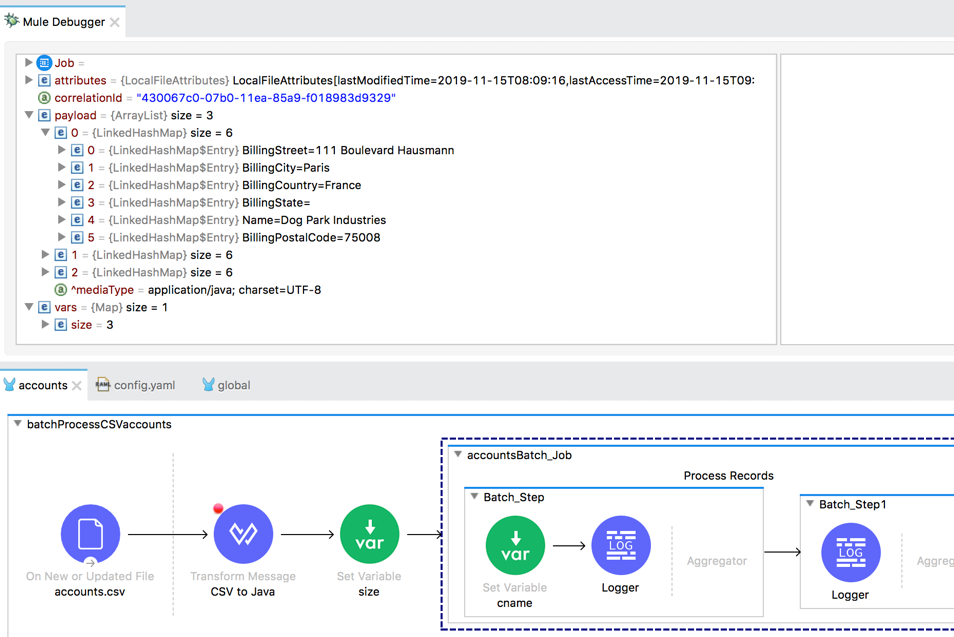
24. In the Mule Debugger view, watch the payload as you step to the Batch Job scope; it should go from CSV to an ArrayList.
25. In the Mule Debugger view, expand Variables; you should see the size variable.
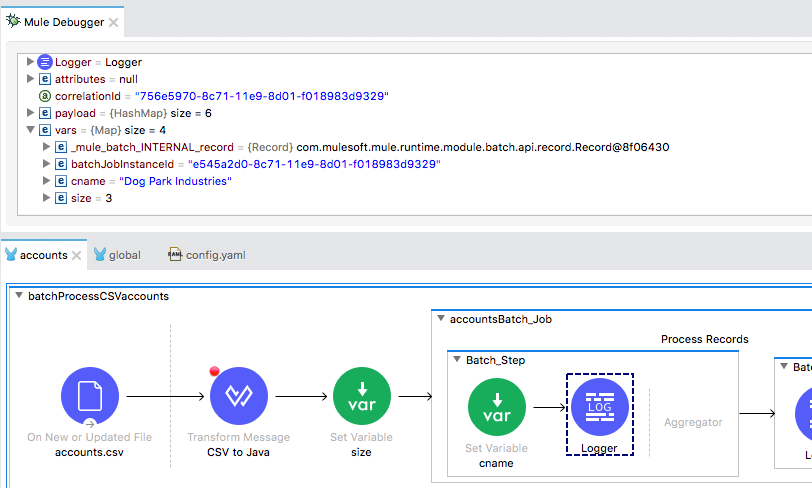
26. Step to the Logger in the first batch step.
27. In the Mule Debugger view, look at the value of the payload; it should be a HashMap.
28. Expand Variables; you should see the size variable and the cname variable specific for that record.
29. Step through the rest of the records in the first batch step and watch the payload and the cname variable change.
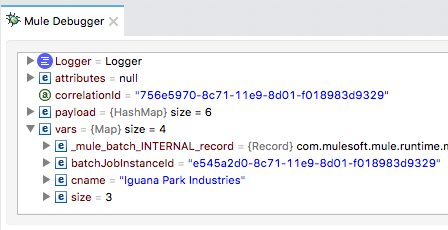
30. Step into the second batch step and look at the payload and the cname variable; you should see the cname variable is defined and has a value.
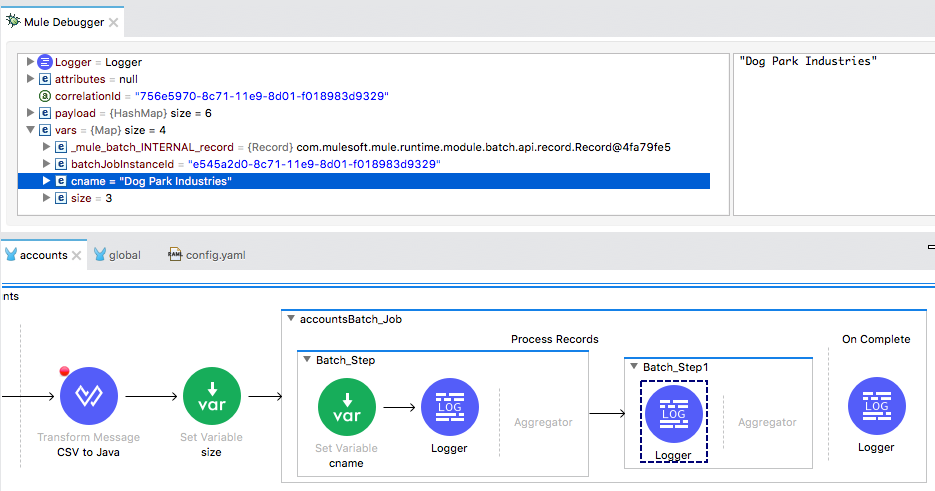
31. Step through the rest of the records in the second batch step and watch the value of cname.
32. Step into the On Complete phase; you should see the payload is an ImmutableBatchJobResult.
33. Expand the payload and locate the values for totalRecords, successfulRecords, and failedRecords.
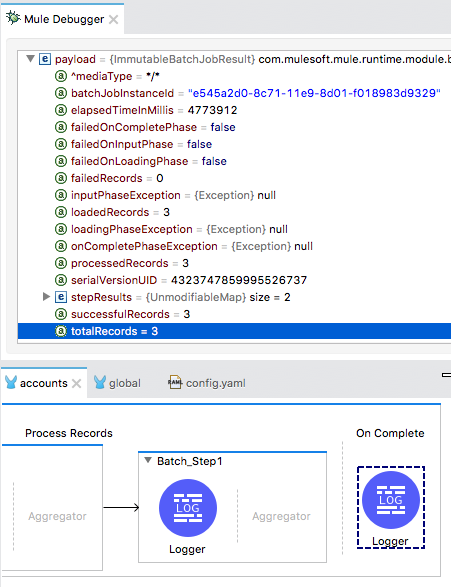
34. Step through the rest of the application and switch perspectives.
35. Stop the project.
Look at the processing threads
36. In the console, locate the thread number used to process each record in the collection in each step of the batch process; you should see more than one thread used.
